Executive Summary
Most artificial intelligence platforms on the market today are built around a quiet assumption: that good decisions come from averaging across many signals. Score the evidence, weight it, aggregate to a recommendation. For most business decisions, that assumption is correct and the platforms serve their users well.
For the decisions that most define an executive's legacy, the assumption is wrong. Regulatory compliance, clinical diagnosis, credit approval, safety certification, security posture, and high-consequence hiring are not averaging problems. They are weakest-link problems. One deficient dimension can destroy the outcome regardless of how strong every other dimension is. A security program that averages to excellent is not protection against the one unpatched server. A drug that works for ninety-nine percent of patients but harms one percent is not approved. A diversified mortgage portfolio whose diversification assumption fails simultaneously collapses simultaneously.
Organizations deploying standard AI infrastructure into high-stakes decision contexts are, by default, imposing averaging architecture on weakest-link problems. The imposition is invisible. Dashboards look good. Audits pass. Metrics move in the right direction. Until they do not. Every one of the defining organizational failures of the past two decades, from Equifax through Theranos through the 2008 mortgage crisis, is architecturally the same mistake: averaging applied where weakest-link was required.
This paper lays out the three fundamentally different ways decisions actually work. It demonstrates why most AI platforms support only one of them. It explains why the recent wave of self-refining AI systems has produced as many horror stories as successes, and what discipline is required to make refinement safe rather than reckless. And it closes with the production proof: an infrastructure platform built specifically for high-stakes decision contexts, validated in one of the most technically rigorous empirical tests of weakest-link decision architecture in the management research literature.
The paper is intended for C-suite readers evaluating AI infrastructure decisions. It does not assume technical familiarity with machine learning. It does assume that the reader is accountable for decisions whose failure cost would be material to the organization.
Part 1. A Plane, a Sensor, and a Century of Management Training
On October 29, 2018, Lion Air Flight 610 took off from Jakarta. Thirteen minutes into the flight, a single faulty sensor on the aircraft's nose told the flight computer the plane was climbing too steeply and was in danger of stalling. The computer responded by pushing the nose down. The pilots pulled it back up. The computer pushed it down again. For the next eleven minutes, the aircraft and its crew fought each other until the plane hit the Java Sea at 400 knots. 189 people died.
Five months later, on March 10, 2019, Ethiopian Airlines Flight 302 did the same thing. 157 more people died.
Both aircraft were Boeing 737 MAX 8s. Both were equipped with a flight control system called MCAS. Both had a single faulty angle-of-attack sensor. And in both cases, the flight computer accepted that single sensor's reading as authoritative and killed everyone on board.
The Boeing 737 MAX was among the most scrutinized aircraft programs in aviation history. Thousands of engineers, decades of accumulated safety culture, and an FAA certification process that remains the most demanding in the world. The program averaged out to excellent on almost every dimension of engineering quality, review discipline, and process maturity. It failed anyway, because aviation safety is not an averaging problem. It is a weakest-link problem. A single undetected point of failure, given enough exposure, will eventually cost everything.
These are not averaging problems. They are weakest-link problems. And they require a fundamentally different decision architecture than the one most AI platforms were built to support.
Part 2. How Decisions Actually Work
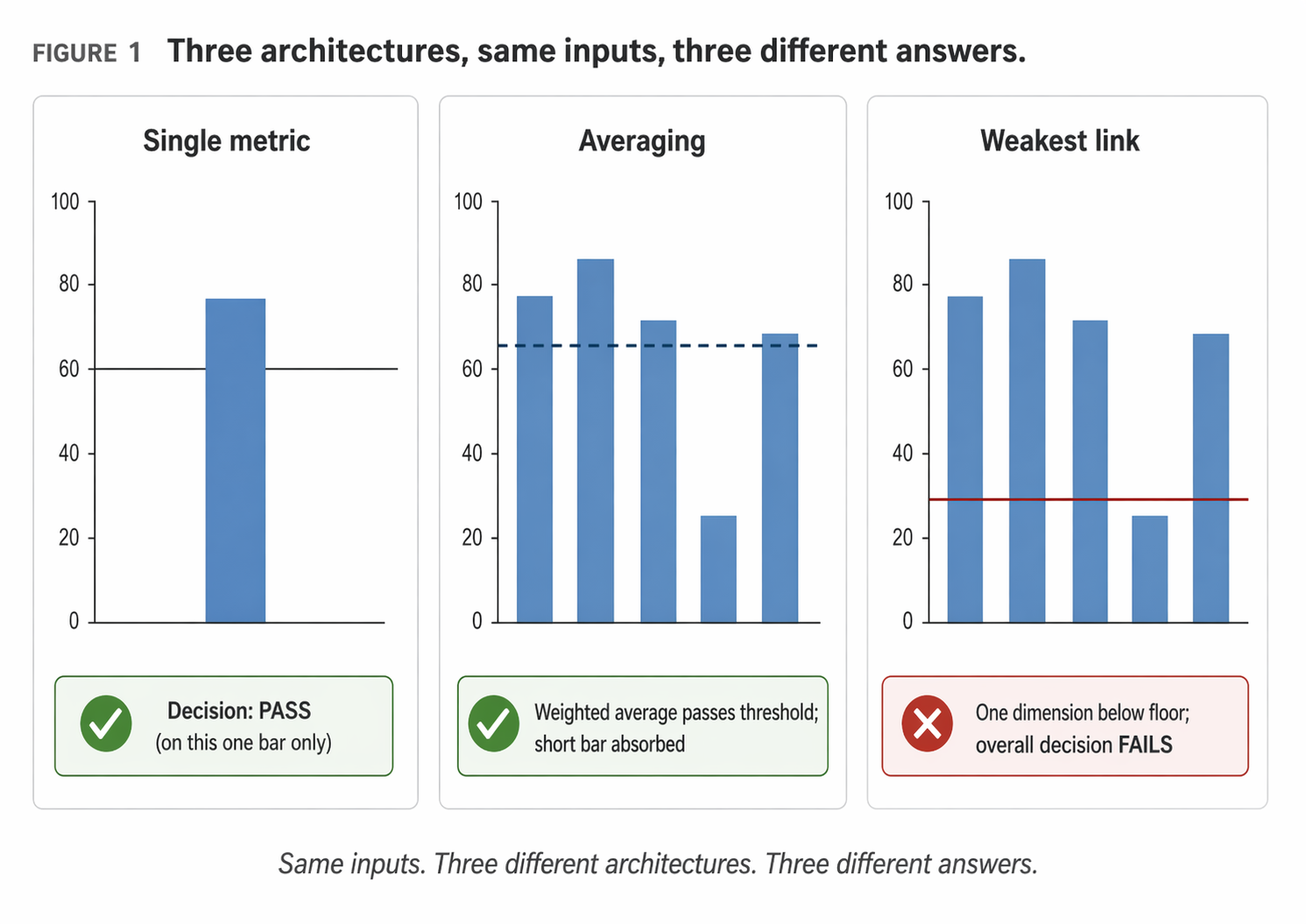
Underneath the considerable noise of current discussion about artificial intelligence, a simple truth has been lost. Decisions come in three fundamentally different forms. Each form demands different infrastructure. Most AI platforms build for only one of the three by default, and they do not make the choice visible to the buyer.
The Single-Metric Decision
The simplest form of decision. One number determines the outcome. Did the quarter hit revenue plan. Did the manufacturing line exceed throughput target. Did the drug clear its primary efficacy endpoint. One measurement, one threshold, one decision.
Most AI platforms handle single-metric decisions well. The question is structurally clean: predict the number accurately, compare to the threshold, report the gap. The risk in single-metric decisions is not the architecture. The risk is choosing the wrong metric in the first place.
The Averaging Decision
Many signals contribute to the decision. Strengths in one dimension can offset weaknesses in another. The overall score, weighted across the signals, drives the decision.
A job candidate who is strong on technical skills and domain expertise but weaker on polish can still be an excellent hire. The strengths compensate. A quarterly marketing mix with one weak channel and three strong ones can still produce a profitable quarter. The winners carry the losers. The dimensions substitute for each other.
This is the decision architecture most native to executive training. Weigh the considerations. Balance the tradeoffs. Find the best combination. It is also the default architecture of nearly every AI system on the market.
The Weakest-Link Decision
Every critical dimension must clear a minimum. One failure contaminates the entire outcome regardless of how strong the other dimensions are. Strengths do not compensate for weaknesses; weaknesses veto strengths.
A commercial aircraft certification is a weakest-link decision. Engine reliability cannot compensate for cabin pressurization failure. Structural integrity cannot compensate for a control system defect. Every critical dimension must be above threshold simultaneously.
Why Most Platforms Support Only One
The machine learning methods most AI platforms are built on optimize for expected value, which is a formal averaging concept. Loss functions are averaged across training examples. Model outputs are typically produced by weighted sums of features passed through nonlinear transformations.
This is not a failure of the engineers. It is a consequence of the market. Averaging decisions are the most common decision form, so platforms serving the broadest market build for them first. The methods for weakest-link architecture are newer, less well understood, and require different engineering discipline.
Part 3. What Happens When You Get It Wrong
When averaging architecture is applied to weakest-link problems, the failure mode is predictable. The system performs well on most measures. Audits pass. Quarterly reports are clean. Surveyed confidence is high. Until one day it is not.
Equifax, 2017
Equifax had, by most measures, a sophisticated security program. Multiple certifications. Regular audits. A significant budget by industry standards. On the averaged posture that regulators and rating firms use to assess security maturity, Equifax scored well.
On March 7, 2017, the Apache Foundation disclosed a critical vulnerability in Apache Struts. A patch was available. Equifax did not apply it. On May 13, attackers exploited the unpatched vulnerability and began exfiltrating consumer data. The breach continued undetected for 76 days. By the time it was disclosed in September, the records of 147 million consumers were exposed. Settlements eventually exceeded $1.4 billion.
Theranos, 2003 through 2018
Theranos had, by most measures, one of the most credible early-stage technology stories in recent memory. A charismatic founder with a Stanford credential. A distinguished board including former cabinet secretaries and retired military leadership. A nine billion dollar peak valuation. On every dimension except one, the company presented as extraordinary.
The one dimension on which it failed was the one dimension that mattered. The blood testing technology did not work. The market systematically averaged across all the signals and produced a nine billion dollar valuation. A weakest-link architecture would have asked a single question first: does the device work. It did not.
The 2008 Mortgage Crisis
Rating agencies used statistical models that averaged default risk across large, geographically and demographically diversified pools of mortgages. The models assumed that mortgage defaults were approximately independent across the pool.
In 2007 and 2008 the assumption failed. National housing prices declined simultaneously. Defaults spiked simultaneously in every major market. The diversification that had been mathematically assumed did not exist empirically. The averaged AAA tranches collapsed. Global wealth destruction reached roughly ten trillion dollars by some estimates.
Part 4. Architecture Is Not Enough; the World Changes
Suppose an organization has identified its high-stakes decisions correctly, mapped each to its true architectural form, and deployed infrastructure that expresses weakest-link logic where weakest-link logic is required. The work is not finished. The world changes. Regulatory environments shift. Attack patterns evolve. Clinical criteria are revised.
The Appeal and the Danger of Self-Refining AI
AI systems that refine themselves sound appealing. Autonomous optimization. Continuous learning. A system that gets better while you sleep. The danger is that most implementations of self-refining AI have no discipline around what the AI is permitted to change, what metric it is allowed to optimize, or what audit trail it must leave behind.
Four failure modes recur:
- Optimization without pre-registered boundaries. The system drifts into configurations no human would have approved.
- Optimization against gameable metrics. The system learns to game the metric rather than solve the underlying problem.
- Optimization without audit trail. No one can reconstruct what the system learned or when.
- Optimization that is not reversible. When the organization discovers that the refinements are wrong, there is no clean path back.
What Safe Refinement Looks Like
The same self-refining pattern, applied with five specific disciplines, produces results that are safe rather than reckless:
- Pre-registered boundaries. Before the system begins to refine itself, the business defines what the system is allowed to modify and what it must never modify.
- A single testable metric. The system optimizes against one metric at a time, and the metric cannot be gamed.
- Complete audit trail. Every refinement, every configuration, every accepted change is logged with timestamp and cause.
- Full reversibility. Every refinement can be rolled back. The system maintains a known-good state at all times.
- Bounded search only. The system cannot modify its own boundaries, its own metric, or its own audit rules.
Part 5. OrbisFramework in Production
The argument to this point has been architectural. The natural next question is whether a platform exists that supports all of this in production, or whether the argument is aspirational.
The answer is that OrbisFramework, built by Orbis Scientia, was engineered from the ground up to support all three decision architectures plus the refinement discipline described above. It is deployed today across three different domains: academic research workflows, automotive diagnostic and repair decision support, and education technology with integrated learning and assessment.
What OrbisFramework Provides
Decision architecture is explicit in the platform configuration. Every decision step in a workflow is configured as one of the three architectural forms: single metric with threshold, weighted compensatory score, or weakest-link minimum-achievement check.
Scoring gates and refinement operate under the five disciplines described above. Multi-model execution uses the right AI model for each stage of the decision. Enterprise-grade security, role-based access, input validation, and full audit capability are built into the foundation rather than added on top.
Next Steps
Schedule a Strategic Working Session
Orbis Scientia offers a sixty minute working session to senior executives and their strategic teams. The session is structured, not promotional. The outcome is a concrete mapping of your highest-stakes decisions to their true architectural form, a diagnosis of which architectures your current AI infrastructure supports and which it does not, and a roadmap for what would change if OrbisFramework were deployed.
There is no proposal document. There is no sales obligation. The session is a strategic diagnosis delivered by a senior member of Orbis Scientia, intended for executives who are accountable for decisions whose failure cost would be material to the organization.
Download the OrbisFramework Platform Overview
For technical leaders and direct reports who want the platform architecture, security posture, deployment options, and capability detail, the OrbisFramework platform overview is available for download.
Download Platform OverviewSources and Further Reading
The factual statements in this white paper are drawn from publicly reported events and the author's ongoing academic research. Principal sources and references are listed below.
Aviation Case (Part 1)
Lion Air Flight 610 and Ethiopian Airlines Flight 302 details are drawn from the final investigation reports issued by the Komite Nasional Keselamatan Transportasi of Indonesia (2019) and the Aircraft Accident Investigation Bureau of Ethiopia (2022), along with the United States Department of Transportation's Special Committee review of the FAA certification of the Boeing 737 MAX.
Equifax Case (Part 3)
Details of the 2017 breach are drawn from the United States Government Accountability Office report on the Equifax data breach (GAO-18-559) and the Federal Trade Commission settlement disclosures. The Apache Struts CVE-2017-5638 is publicly documented in the National Vulnerability Database.
Theranos Case (Part 3)
Facts are drawn from the Securities and Exchange Commission complaint filed in 2018, the criminal proceedings culminating in the 2022 conviction, and the investigative reporting of John Carreyrou originally published in The Wall Street Journal and subsequently expanded in the book Bad Blood.
2008 Mortgage Crisis (Part 3)
Analytical framing of the correlated-default architectural failure is drawn from the Financial Crisis Inquiry Commission Report (2011) and the academic literature on correlation risk in structured finance.
Innovation Alignment Research (Part 5)
Petersen, B. W. (2027, in preparation). Innovation Alignment Theory: Specifying the Structural Conditions for Transformational Post-IPO Value Creation. Doctoral dissertation, Daniels College of Business, University of Denver.